Amjad Masad
Or, what I wish you I knew before building Repl.it's code execution service

new drinking game "name that AWS service logo"
— TJ Holowaychuk (@tjholowaychuk) March 23, 2016
I, by no means, identify as a devops or even a backend engineer. Most of my professional experience has been equally split between frontend/product and developer tooling. I also primarily learn by doing and bias towards simplicity and MVPs -- almost to a fault. So when I approached building a service on AWS I took a very simple path and increased complexity as the service scaled up. Here are all the steps that I went through before getting to something that I'm not totally ashamed of.
eval.repl.it
Repl.it is a simple yet powerful in-browser development environment. Initially we ran only languages that could be compiled to JS and run in the browser. However, as we added more features -- such as filesystem access -- and wanted to add more languages we needed to migrate to a server-side solution. I wrote the service in Go, Docker, and multiple other languages responsible for evaluating code in their respective environment.
It's a tricky service to build, secure, scale, and monitor, however, this is not what this post is about. It can easily apply to most other web services.
ssh, checkout, and start
EC2 instances are virtual private servers (which is the fundamental building blocks for cloud computing). So I booted one up (relatively straightforward), ssh'd into it, git cloned my repo, added my service to Ubuntu upstart and called it a day. A few days after we launched, the service went down from an OutOfMemoryError. After using larger and larger instances (adding CPU, Memory, disk space, i.e. vertical scaling) the service kept getting more popular and having one instance meant a single point of failure.
Horizontal scaling
To avoid a single point failure and since there are limits to how much vertical scaling we can do, we can start thinking about adding more machines.
(However, before jumping into horizontal scaling you need to externalize any in-memory state into a shared resource like Redis).
Luckily, another great tool in the EC2 toolbox is AMIs. AMIs are immutable images used to launch pre-configured EC2 instances. After configuring and deploying code to your EC2 instance you can create an image from it. Afterwards, you can launch as many instances with that image as you want.
But now something needs to do the routing to the different instances. For that, we can use AWS's Elastic Load Balancer. It's really easy to create, configure and add instances to.
A quick note on websockets
ELB, up until recently, didn't have support for websockets. Now, you can launch what's called an Application Load Balancer which has first-class support for Websockets. For classic ELB you're stuck with using TCP which has multiple quirks with the most pressing issue you might run into is that it does round-robin routing. That means that it will distribute connections to the backends by cycling deterministically between them. Since websockets are long-running connections it's only a matter of time before you have one instance carrying a much bigger load while others are starving. For this I had to build all sorts of bells and whistles but I'll spare the details on -- just try to use the new thing (I haven't tried it yet).
Failing at scale
Luckily for our product, our company and the people we serve we continued to grow. Unlucky for me, founder, CEO, engineer, and now Devops, at scale things starts to fail in unexpected ways. For example, hardware might fail and your instance can become unreachable. To add insult to injury, Amazon will send you an email that sounds like an obituary "Amazon EC2 Instance scheduled for retirement".
Going in, launching and adding instances to the load-balancer proved to be too time consuming (also meant that I'm always on-call, although that's generally a problem when you're starting up).
Automation, yay!
I take it that a corner-stone of Devops is automation. There is an entire industry of tools that simplifies provisioning and deploying new machines. However, I decided to stick within the confines of point-and-click AWS since it worked well thus far. But this was the hardest step to figure out. Essentially if you want to automate scaling and deployment you need to learn the following things and the inter-play between them:
- Codedeploy: a service that automates checking out a git revision of your code into an EC2 instance
- EC2 Launch Configuration: lets you create configuration (size, image etc) of EC2 instances that you want to launch
- EC2 AutoScaling group: lets describe how many instances you want to launch and deploy and the policies used to scale up or scale down.
After some research I figured out that I needed all those things and what they do. I first created the launch configuration with my AMI id and the configuration that I used to put in manually every time I launched an EC2 instance. Then, I created the AutoScaling group on top of the launch configuration. Finally, I signed up for Codedeploy (it's not part of EC2) and had it linked to the AutoScaling group.
Now every time a new instance is launched Codedeploy will checkout your code from Github (or S3) and place it in a predefined path. It also allows you to define lifecycle hooks that you can use to shutdown your service, do any cleanups, installation or what have you before starting it back up again. Here is a flowchart from the AWS docs on how Codedeploy works with AutoScaling.
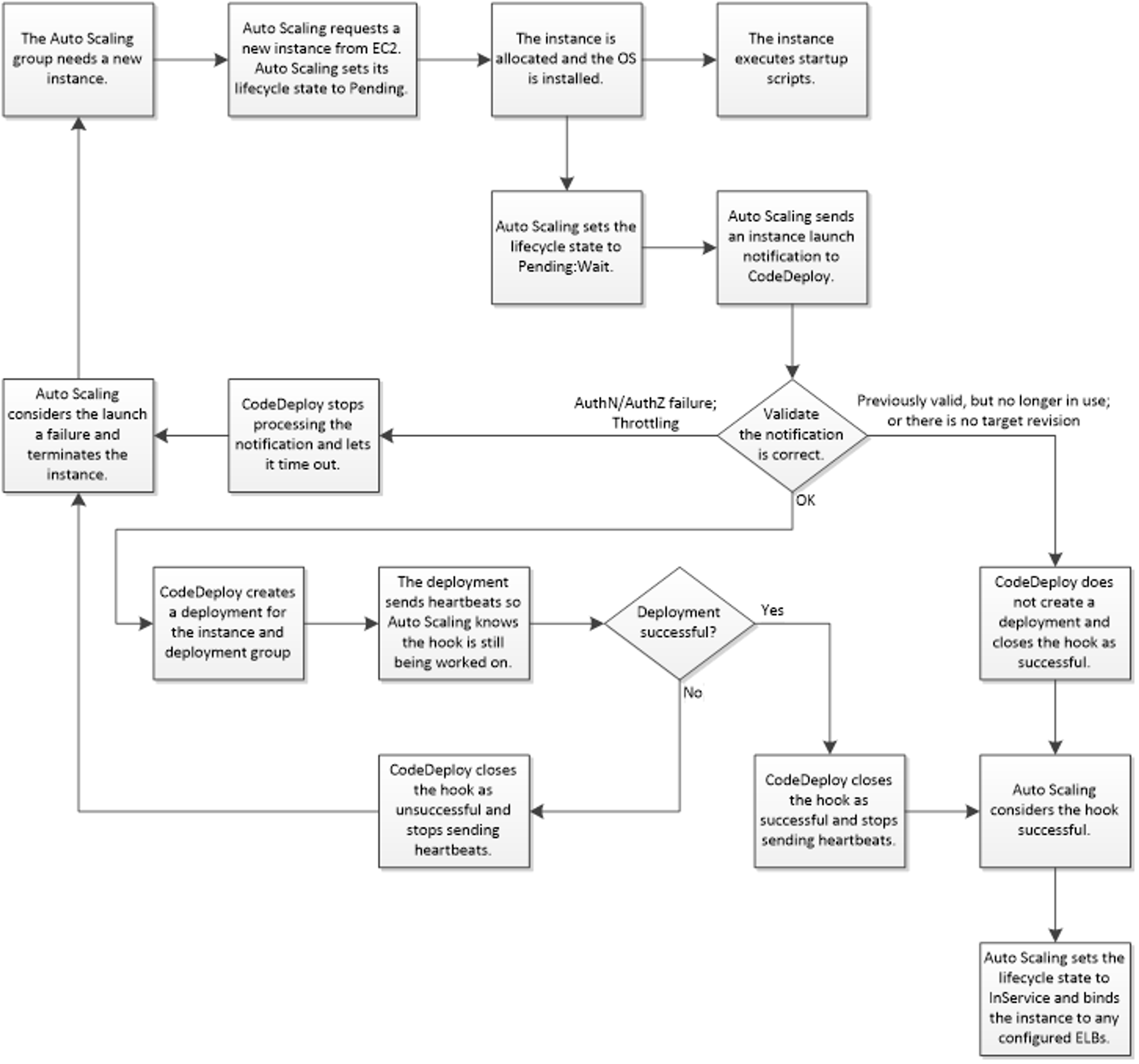
Finally, when you want to deploy a new revision of your code you put your commit sha into a Codedeploy form and it runs on your machines to update and re-launch your app. Feels too good to be true. And it kind of is.
Codedeploy woes
Codedeploy solves a real need for people like me who are not professional DevOps. I can have continuous-deployment-like service without building all the custom infrastructure companies usually have to build.
However, there were some issues that made it unreliable and eventually unusable for me:
- Lack of visibility over the deployment. Errors are cryptic and logs are truncated. It seems like it should just stream the logs from the deployment immediately back to the website. But it doesn't.
- Lack of comprehensive deployment strategies. While deploying, your instance will be removed from the load-balancer rotation, so deploying on all machines at once meant a downtime. The only option to do zero-downtime is the "one-by-one" deployment, however, if only one machine fails to deploy, say a transient failure in the installation process, it will rollback the entire deploy.
- There are some bugs with the system that someone on the Codedeploy team told me are being fixed. But I had issues with race-conditions between the AutoScaling, load-balancer and Codedeploy. And issues with the deploys going on forever and timing out after an hour or so.
This meant that deployment for us often took down the service and was very painful. On the flip-side the Codedeploy team is responsive and seems eager to fix those issues.
Taking the big step: Ansible
Now that I have a good understanding of EC2's building blocks, I'm ready to move on to a real automation tool: Ansible. I first flirted with Ansible in my development environment. I use Vagrant and I needed a reproducible way to build development machines. As a React engineer when I took a look at Ansible, it immediately made sense. It's adding a layer of idempotency using a declarative language over a highly stateful and mutative process. Similar to how React sits on top of the DOM and makes it nice to talk to.
Luckily, after some googling I found this amazing step-by-step guide to automating my EC2 setup (AMIs, load-balancer, AutoScaling).
I spent the past few days writing yml files to describe the different my ec2 configuration. It went really well, and now I can launch an entirely new cluster in 30 minutes. This makes it easy to deploy often and with confidence.
Conclusion
Now, instead of taking a day off to deploy and always be on the look-out for fires we can move a lot faster on features. Someone with experience may have skipped everything and jumped to the last step but:
- It would've been an over-engineered solution given that nobody was using the service on day zero.
- It was a great opportunity to really internalize what every tool I added to my arsenal did.
I'd happily take a bit of beating instead of cargo-culting my way out of engineering problems.
If you have experience with this sort of stuff then consider joining our small team, we're growing very fast and I'm sure this is not the end of the scaling journey. Email us: [email protected]