Abhishek Bhardwaj

Luis Héctor Chávez

Connor Brewster
At Replit, session success rate is one of our service level objectives (SLOs). This means that any legitimate incoming request from a client should always be successfully connected to its target Repl. Failure to do so is a bad user experience.
To abstract away intermittent infrastructure failures when you connect to a Repl, we use a reverse WebSocket proxy between the user’s client and the remote VM hosting Conman, our container manager that runs all Repls in a container. The high-level view of this proxying looks something like this:
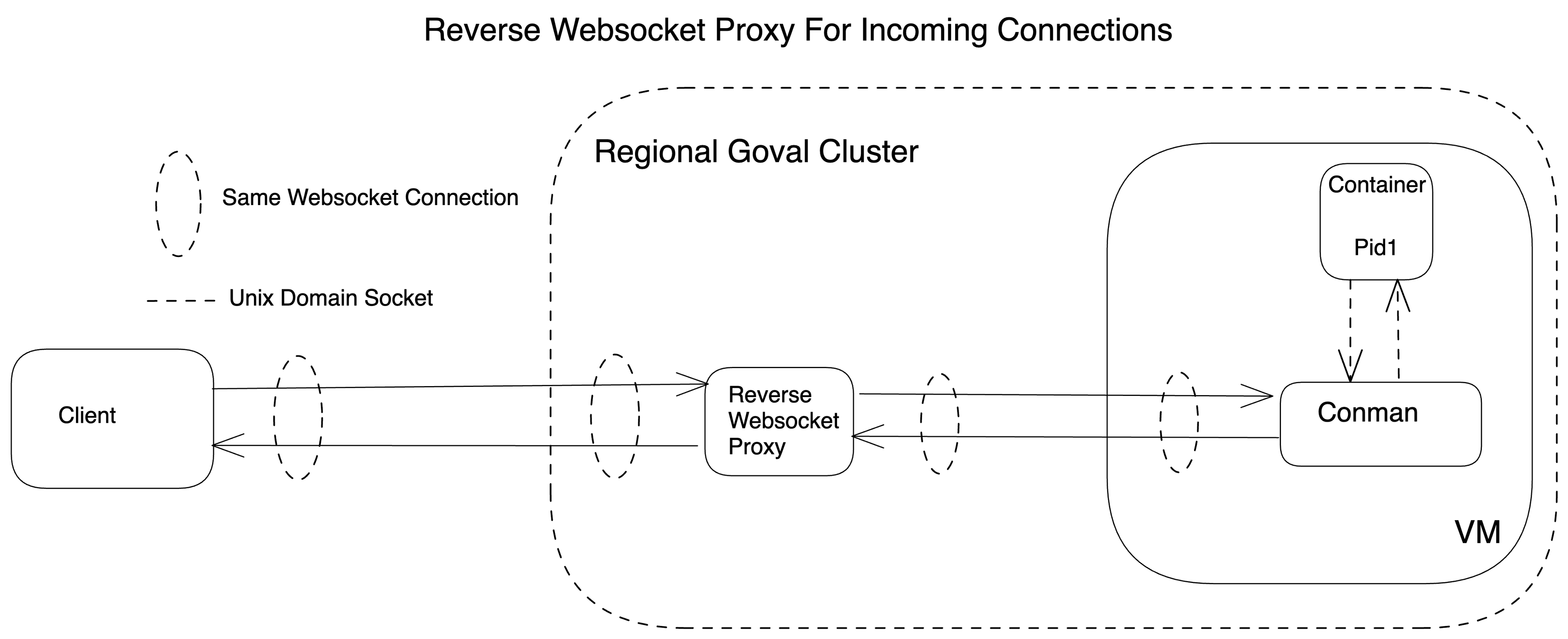
In the above diagram, Regional Goval Cluster represents our backend, which is sharded per region for scale and to prevent cross-region latency and egress costs. You can read more about it in this blog post. The diagram illustrates that the reverse WebSocket proxy can attempt a retry if any failures occur during the connection setup with Conman. The proxy is alive throughout the connection and transfers data back and forth between the client and the user’s Repl.
The problem
Everything seems architecturally sound here, so what was the problem? Conman, technically our container manager and responsible for running Repls in containers on GCE VMs, also doubled up as our reverse WebSocket proxy. Here’s what our architecture and overall flow used to look like:
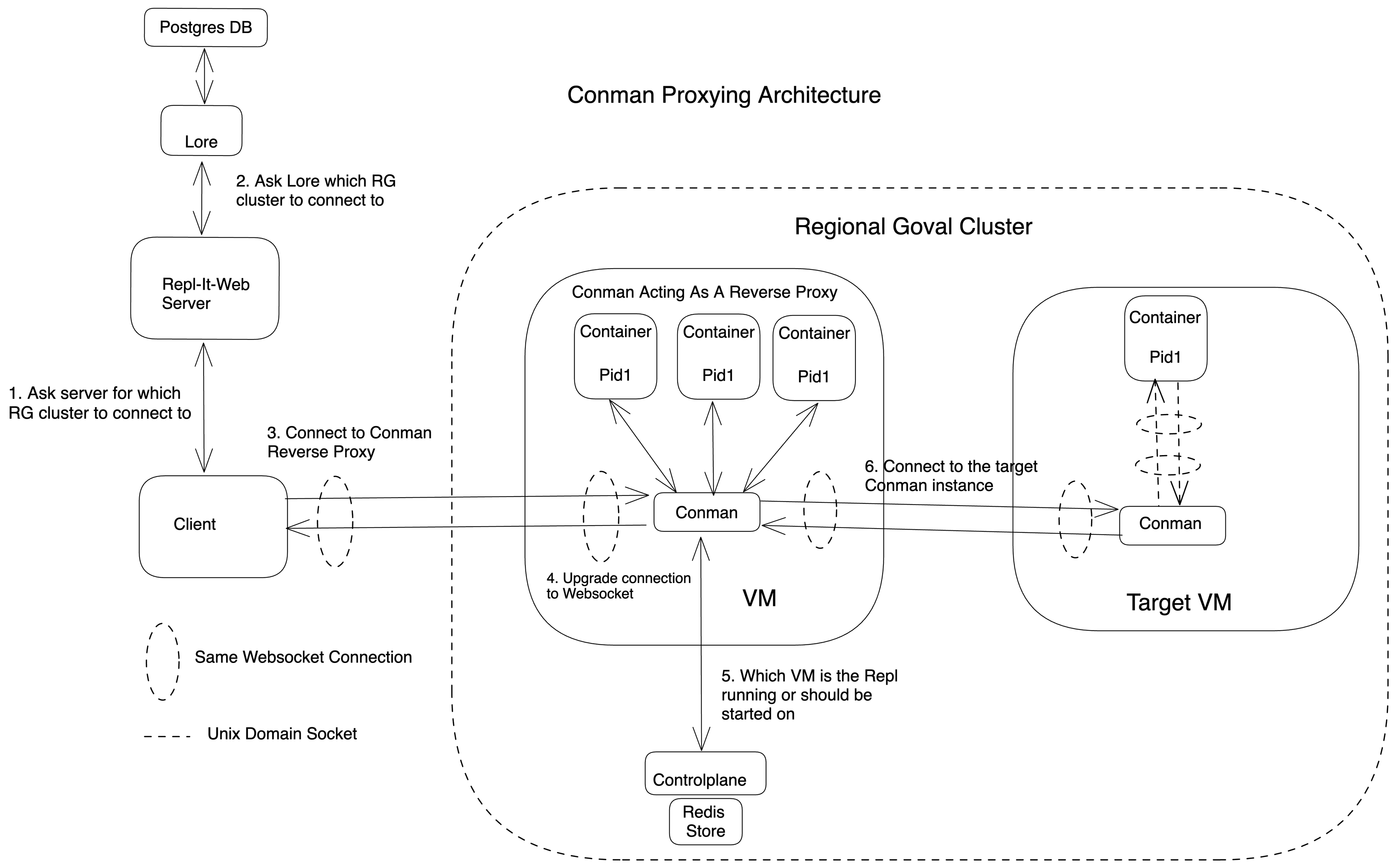
The above diagram shows our previous architecture, where Conman acts as a reverse proxy. This architecture has the following disadvantages:
- Conman has a large surface area and is constantly updated. However, to avoid interruptions for our users, Conman instances must also be alive for the duration of each client connection. This isn’t the case today– whenever we have Conman updates, Conman VMs destroy their containers and shut down. This causes a disconnect for a client when the proxying VM dies, and an additional one when the target VM dies. Thus, a client can disconnect multiple times during an update as its proxying or target VM is shutting down.
- Conman’s sole job is to run containers. However when it's acting as a reverse proxy, if the Conman VM goes down, the Repls it’s hosting and proxying through itself both get interrupted connections.
- We would like to autoscale the number of Conman VMs solely based on the number of containers each VM is running. Sharing its resources with reverse proxying makes this autoscaling logic complicated.
- In practice, Conman code has both the container hosting and proxying code, and it's hard for the team to diagnose the exact cause of the session failures (i.e., how many legitimate incoming requests we failed to connect to their Repls). This makes diagnosing and fixing session failure rates harder.
The solution
To address the concerns raised above, we’re introducing a new service called Eval, our new reverse WebSockets proxy, which sits between the client and Conman VMs. Conman can solely be a container manager and doesn’t have to worry about proxying incoming connections. Here is the new architecture:
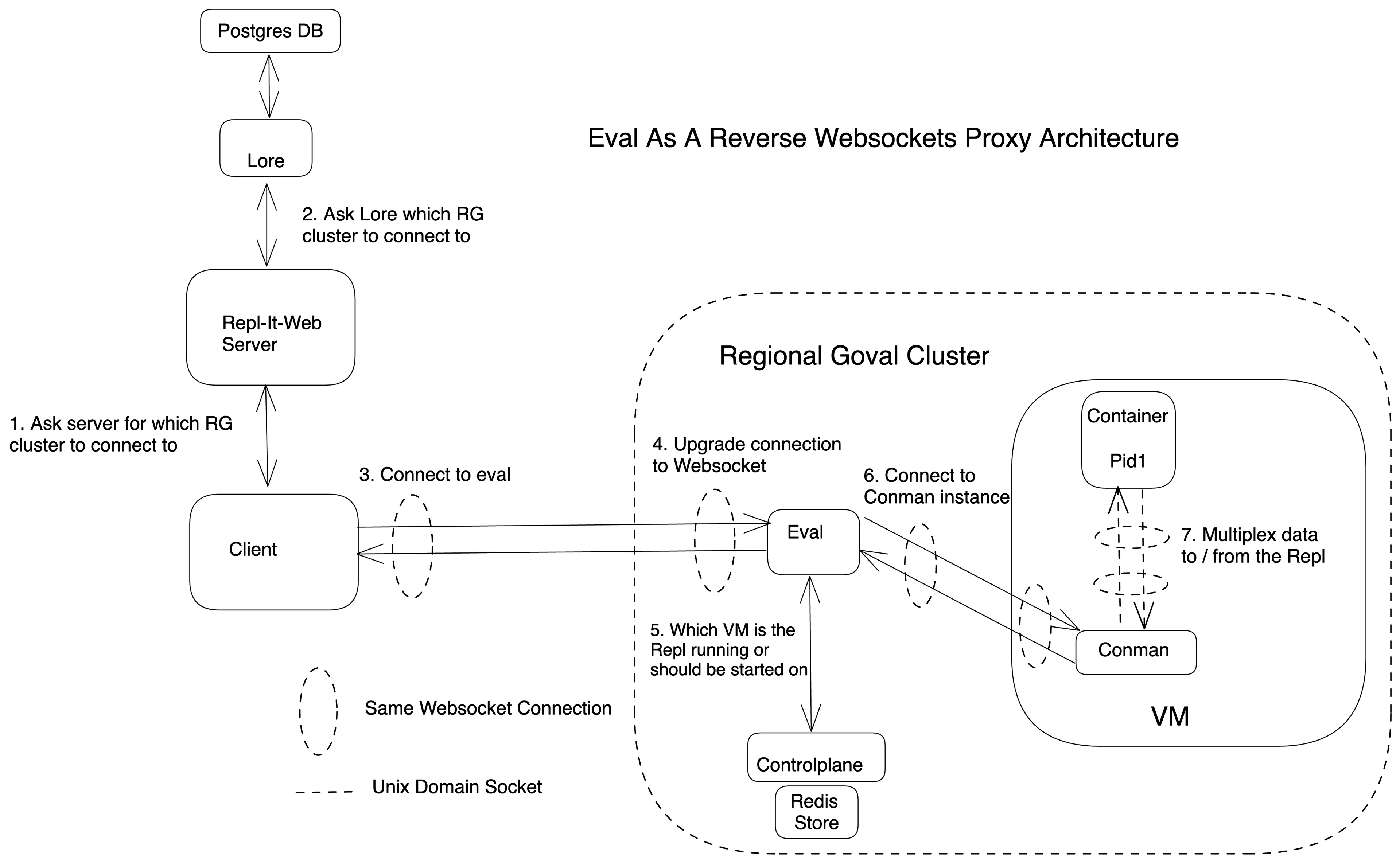
Connection flow
With Eval as our new reverse proxy, let’s go over how a client establishes a connection to a Repl:
- The client navigates to “replit.com/@<username>/<replname>”.
- This action leads to a request to a repl-it-web server to ask which regional Goval cluster the client should connect to.
- The server talks to Lore to gather more information about the Repl’s cluster and other metadata. Lore is a slim single point of failure service that tells clients where to connect.
- The server responds to the client with the URL of the Eval instance to connect to and a token.
- The client now sends a request to a dedicated WebSocket endpoint on the Eval URL it received from the server.
- This request reaches Eval and it upgrades the client’s connection to a WebSocket connection.
- Eval talks to our Controlplane service to query which VM the Repl is currently running on or which VM it should run on. This step is part of our load-balancing logic: Controlplane chooses the new VM based on which VM is best suited to place the new Repl.
- Eval then establishes a WebSocket connection with the remote Conman instance.
- Conman forwards data to / from the Repl associated with this request.
- Thus, Eval has established WebSocket connections with the client and the Conman VM and copies data back and forth between them. It needs to be alive for the duration of every connection it’s serving.
Advantages
This new architecture gives us the following advantages:
- Frequent Conman rollouts now only bring down the target VM and not the reverse proxy, Eval. This means that the client only gets one disconnect event instead of possible multiple events during a Conman update.
- To avoid disruptions on Eval updates, we configure Eval to have a long grace period on an update or shutdown (30h+). This wasn’t possible with our previous architecture. This means that Eval will wait for all its connections to shut down before it shuts down itself.
- Eval has a smaller functionality surface and the chances of it going down are lower compared to Conman. Overall it means more reliable connections to Repls for our users due to fewer reverse proxy failures.
- Eval is solely dedicated to reverse proxying and takes that functionality away from Conman. This means that we have minimal Conman instances running old builds at any given time.
- Eval can be scaled up and down easily based on the number of active client connections. It doesn’t need to share its resources for other unrelated functionality.
- Eval’s observability is set up to clearly delineate which part of setting up the proxy failed i.e., was the token sent by the user invalid, did we fail to talk to the Controlplane? Or did we fail to talk to the remote conman VM? This has made diagnosing session failure rate spikes far easier than before.
Conclusion
We’ve introduced a new reverse WebSockets proxy called Eval which will help us meet our SLOs and reduce instances where we can’t connect a client to its corresponding Repl. In case of errors, it lets us easily diagnose which part of our infrastructure is failing. If any of these challenges seem interesting, we would love to hear from you - check out our Careers page.